
Óscar Fernández Nuñez
Técnicas de optimización en Apache Spark
Optimizar Spark es clave para acelerar el procesamiento de grandes volúmenes de datos. Desde el uso de formatos eficientes como Parquet hasta la gestión de memoria, particiones y joins, cada ajuste puede marcar la diferencia. Descubre cómo sacar el máximo rendimiento a tus procesos distribuidos.
Spark es un motor de procesamiento distribuido de datos OpenSource, enfocado en el tratamiento de grandes volúmenes de datos.

Algunas de sus principales características son:
Desarrollado en Scala, permite a los desarrolladores trabajar con diferentes lenguajes de programación como R, Python, Java o el propio Scala (principalmente se trabaja con Scala o Python).
Incluye un conjunto de librerías para tratar distintos ámbitos del dato:
MLlib: Machine Learning
Streaming: Datos en tiempo real
SQL: Datos batch, la API te permite trabajar en código SQL
GraphX: Generación de gráficos
El motor está basado en memoria, aumentando significativamente la velocidad de procesamiento.
Permite trabajar con diferentes fuentes de datos no estructurados, semiestructurados o estructurados.
Permite trabajar con diferentes sistemas de archivos, así como bases de datos relacionales y no relacionales.
Escalabilidad bajo demanda y de forma sencilla.
A continuación, explicamos algunas técnicas de optimización que hemos utilizado en proyectos de diferentes tipologías:
Trabajar con los datos que realmente sean necesarios
Puede parecer una obviedad, pero trabajar con los datos estrictamente necesarios es fundamental y pilar esencial en cualquier proyecto Data.
Antes de comenzar cualquier proyecto, es esencial hacer un análisis previo que nos permita identificar qué datos y columnas son realmente importantes.
Selección del formato de archivo adecuado
Una de las características más importantes en Spark, es la compatibilidad con multitud de formatos de archivos, pero no todos son igual de óptimos.
Por encima de formatos no estructurados (ej: ficheros de texto plano) y semiestructurados (ej: archivos json), hay un formato que destaca: Parquet.
Parquet es un tipo de fichero basado en columnas y mucho más eficiente en el uso de memoria y almacenamiento, usar este tipo de formato siempre que se pueda, nos ayudará a optimizar el proceso.
Sin embargo, dependiendo del caso de uso, debemos elegir el formato de archivo correcto para equilibrar el rendimiento y las necesidades.
Caché
Controlar la memoria y saber qué debemos cachear, puede evitar procesamientos repetidos e innecesarios, algo que penaliza notablemente en las ejecuciones.
Spark permite cachear en memoria o en disco, e incluso en ambos a la vez, en función de las necesidades. Para ello, tenemos dos posibilidades:
cache(): Almacenamiento de datos sólo en memoria.
persist(): Almacenamiento de datos configurable en memoria, disco o ambas.
Gestión de la memoria
El motor de procesamiento de Spark está basado en memoria, siendo muy importante la configuración de ella, en función de las necesidades.
La memoria en Spark se divide en 3 partes:
Memoria reservada: Se reserva un mínimo para procesos externos del SO.
Memoria de usuario: Se almacenan estructuras de datos u otro tipo de funciones, reservando en torno al 25% de la memoria en ello, siendo configurable.
Memoria de proceso: Se almacena el propio proceso Spark, reservando en torno al 75% de la memoria en ello. Se divide en 2, ambas al 50%:
Memoria de almacenamiento: Reservado para almacenamiento de datos (cache/persist).
Memoria de ejecución: Reservado para el proceso.

Esta distribución y configuración explicada, es totalmente configurable para optimizar nuestros procesos.
Por ejemplo, si tenemos un proceso donde apenas necesitamos cachear datos, podemos disminuir el % de memoria reservado a almacenamiento y aumentar ese % en la memoria reservada para ejecución, otorgando mayor potencia a lo que realmente necesito.
Broadcast Join
Es una técnica de optimización diseñada para la unión de DataFrames grandes (conjunto grande de datos) y DataFames pequeños (conjunto pequeño de datos).
La unión de dos conjuntos es una de las operaciones más costosas en Spark, debido al intercambio de datos que se realizan entre todos los nodos, denominado shuffle.
Cuando uno de los conjuntos es lo suficientemente pequeño como para caber en la memoria de cada nodo, se puede enviar el conjunto a todos los nodos, evitando la operación mencionada anteriormente, optimizando notablemente el proceso.
Ajuste de las particiones shuffle
Como hemos mencionado en el punto anterior, la distribución de datos entre nodos es una de las operaciones más costosas en Spark y se conoce como shuffle. Hay operaciones como uniones o agrupaciones que generan shuffle porque requieren mover datos para ser procesados.
Spark tiene configurado un número de particiones por defecto cuando se va a realizar una acción que genera shuffle, concretamente 200:
spark.conf.set("spark.sql.shuffle.partitions", 200)
Este valor es configurable, pero ajustarlo adecuadamente a nuestro caso de uso, es una de las tareas más complejas e importantes de cara a optimizar un proceso Spark.
Reducir o aumentar este parámetro puede mejorar de forma notable el rendimiento del proceso.
Predicate Pushdown
Esta técnica consiste en acercar los filtros (equivalente a las cláusulas WHERE en SQL) lo más posible a la lectura de las diferentes fuentes de datos del proceso, con el objetivo de que sólo se recuperen los datos estrictamente necesarios y omita fragmentos de datos irrelevantes.
Es importante resaltar que está técnica no es posible con cualquier formato y que se usa principalmente para archivos Parquet, siendo uno de los formatos más potentes en Spark, tal y como hemos mencionado anteriormente.
Configuración clúster
Sacar el máximo partido posible al entorno donde se ejecuten los procesos, puede marcar la diferencia de forma sustancial en los tiempos, siendo fundamental entender bien la arquitectura de Spark:
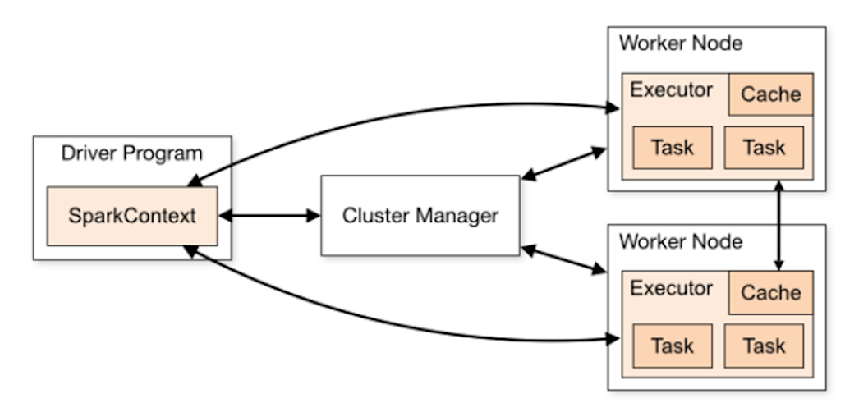
Spark utiliza una arquitectura maestro-esclavo, formada por un nodo maestro y nodos ejecutores, que son los que se encargan de realizar las tareas:
Spark Driver: Coordina la ejecución y de crear la denominada SparkContext, punto de entrada de las tareas en Spark.
Cluster Manager: Administra el cluster y asignar recursos.
Workers: Ejecutan las tareas del proceso Spark. Cada worker puede tener varios ejecutores, responsables de las tareas o almacenamiento de datos en memorio/disco.
Task: Es la unidad de trabajo más pequeña en Spark y representa una unidad de procesamiento por cada partición de datos.
Definida a alto nivel la arquitectura de Spark, es importante configurar determinados parámetros del clúster, que nos permitan trabajar lo más optimo posible con los procesos Spark dentro del cluster:
Paralelismo: Máquinas x núcleos
Ejecutores: Núcleos totales/núcleos por ejecutor
Memoria: Memoria por máquina/Ejecutores por máquina
Supongamos que tenemos un cluster con 20 nodos y 16 cores - 64GB por cada máquina, sabiendo que 1 core y 2GB se recomienda siempre obviarlo, reservándolo para tareas del SO, por lo tanto, nos quedan 20 nodos y 15 cores - 62GB por máquina:
Paralelismo: 20*15 = 300 tareas
Ejecutores: 300/5 = 60 ejecutores
Ejecutores por máquina = 60/20 = 3 ejecutores
Memoria: 62/3 = 20GB
Este es sólo un ejemplo de configuración, el desafío es ir ajustando estos parámetros hasta dar con la tecla adecuada, porque cada entorno y procesos tienen unas condiciones específicas.
Optimizar procesos en Spark es crucial para cualquier proyecto, sin importar el caso de uso. Realizar un análisis previo, desde lo funcional hasta lo técnico, puede marcar la diferencia para obtener procesos más rápidos y eficientes.
>>> Podría interesarte

Blanca Lendoiro Valle
PWA: ¿siguen siendo una opción?
Las Progressive Web Apps (PWA) siguen siendo una opción viable en 2026, pero su papel ha cambiado frente a soluciones nativas y cross-platform maduras. Este análisis evalúa sus fortalezas, limitaciones y casos de uso estratégicos. Descubre cuándo realmente conviene apostar por PWA y cuándo otras alternativas son más efectivas.

Blanca Lendoiro Valle
Cómo elegir el stack de JavaScript adecuado para cada solución
Elegir un stack en el ecosistema JavaScript puede parecer, a primera vista, una cuestión puramente técnica. El ecosistema es enorme: React, Angular, Vue, Node.js, Next.js, Nuxt, Remix, SvelteKit… y cada opción tiene sentido en un contexto distinto. Ahí es donde reside la complejidad real.

Enzo Andrés García Ramírez
NestJS: estructura, velocidad y escalabilidad para tu backend en Node.js
El verdadero valor de NestJS no está solo en su arquitectura o sus herramientas, sino en cómo transforma la forma de trabajar con Node.js. Mientras muchos proyectos pierden velocidad al crecer por falta de estructura, NestJS ofrece una base modular, tipada y escalable que permite mantener la agilidad sin caer en el caos.